What is data integration?
Data integration is a common process in the modern data ecosystem that enables organizations to connect to a data source using a purpose-built connector to bring data into another system for further processing or analysis. This is crucial for businesses to utilize integration tools to derive actionable insights from their data to support decision-making and drive strategic initiatives.
Data integration automates and streamlines the management of data across systems. The data integration process encompasses a range of techniques and methodologies, including ETL (Extract, Transform, Load), data replication, and virtualization, to ensure that data, regardless of its source, can be accessed and analyzed in a consolidated manner.

Data integration systems utilize connectors to integrate data into another system for further processing or analysis.
Considerations when choosing a data integration solution
Managing your data pipelines and choosing the right data integration platform can be a game-changer for your business. It can streamline operations, enhance decision-making, and unlock new opportunities for innovation. With the vast array of tools and technologies available, selecting a solution that aligns with your business requirements, technical capabilities, and strategic goals is crucial.
Consider these points as you evaluate data integration solutions.

Business Objectives and Requirements
Identify what you aim to achieve with the integration, such as improved data quality, real-time analytics, or streamlined operations.
Consider the types of data you need to integrate such as, customer data or financial data, and from which sources (e.g., CRM, ERP).

Data Volume and Complexity
Assess the volume of data that will be handled and the system’s capability to scale as data grows.
Consider the complexity of the data structures and the need for data transformation.

Integration Capabilities
Check if the solution supports different integration styles such as ETL (Extract, Transform, Load), real-time streaming, or batch processing.
Evaluate the ability to connect to various data sources and destinations, including cloud services, databases, and third-party APIs.

Performance and Scalability
Look at the performance benchmarks, particularly how the system performs under load.
Ensure the solution can scale horizontally or vertically based on future needs.

Compliance and Security
Determine the security measures provided, including data encryption and secure data transfer protocols.
Assess data governance capabilities, such as data auditing, lineage, and cataloging.

Ease of Use and Maintenance
Consider the user interface and ease of use for technical and non-technical users.
Evaluate the maintenance support offered by the provider, including customer service, updates, and patches.

Cost
Review the pricing structure, including initial setup costs, licensing fees, and ongoing operational costs.
Consider the total cost of ownership over time, including upgrades and additional services.

Vendor Reputation and Support
Research the vendor’s reputation in the market, their stability, and customer reviews.
Look at the level of technical support provided, including the availability of training resources and community support.

Flexibility and Customization
Check if the solution can be customized to fit specific business needs and how easily these customizations can be implemented.
Assess the flexibility of the solution to adapt to new technologies and integration patterns in the future.

Trial and Testing
If possible, conduct a proof of concept or trial to see how the solution fits with your existing systems and meets your integration needs.Our data integration solution is the key to your success
Tom Sawyer Software has spent more than three decades working with data and has a proven track record of providing solutions that address the data silo issue.
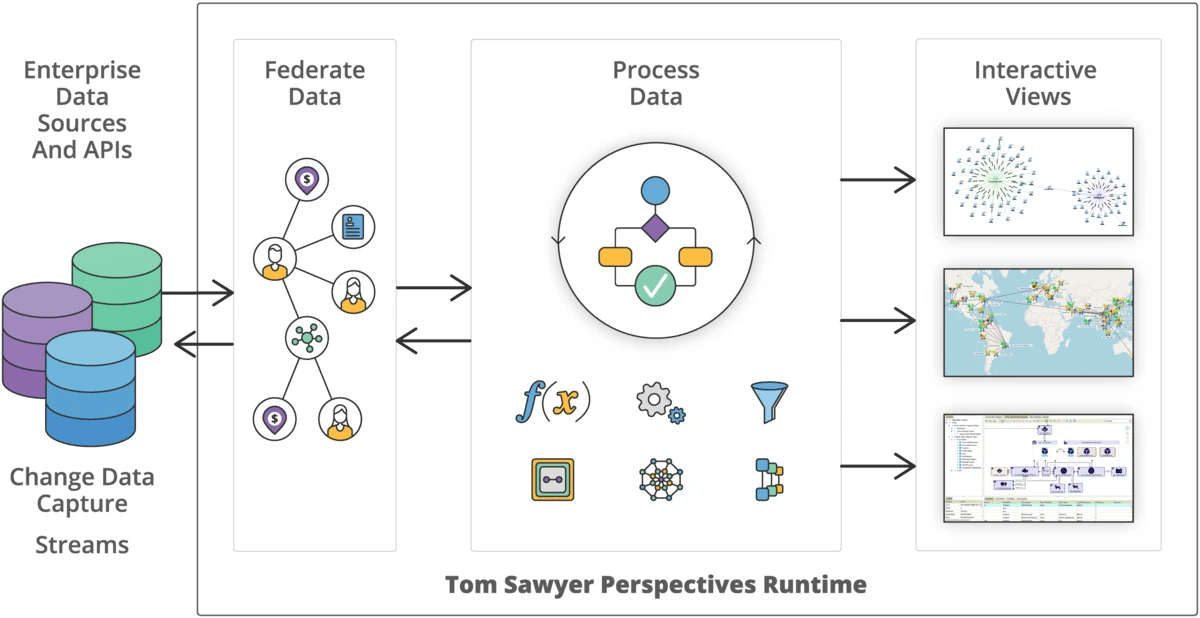
Our mature data integration platform, Perspectives, supports multiple data sources and formats providing the ability to integrate data from a wide range of sources, from graph and relational databases, to cloud services, APIs, and more.
Perspectives is capable of handling large volumes of data efficiently and scaling as your business needs grow.
Once integrated, Perspectives provides real-time access to a unified view of the data and capabilities to reveal valuable insights through powerful visualizations and analysis.
Supported data integrators
The Perspectives platform is data agnostic. It includes a comprehensive set of data integrators that can populate a model from a data source. Some integrators are a bidirectional bridge between a data source and a model, and support writing model data back to the data source.


Commit configuration
With Perspectives, commit configuration is convenient and easy putting you in control of which changes to commit. By default, automatic bindings for Neo4j, Neptune Gremlin, Neptune openCypher, Kuzu, OrientDB, and TinkerPop integrators conveniently handle the commit operations to automatically save all changes. But you can choose to exclude any attributes from being committed. And the system supports regular expressions.
Learn more about the graph editing capabilities in Perspectives.
The benefits of data commit are clear
Perspectives provides all the advantages of model persistence while eliminating the pains associated with it.

Real-Time Updates
By writing changes directly to the original data source, you can provide real-time updates to the data without delays. This is particularly important in applications where up-to-date information is critical, such as financial systems, real-time monitoring, or collaborative editing tools.

Data Consistency
Writing data back helps maintain data consistency. When you update the data source immediately after modifying it, you ensure that all users or components working with that data see the same changes. This prevents data discrepancies or conflicts.
Historical Tracking
Committing changes in the original data source can provide a complete historical record of all modifications made to the data. This audit trail can be invaluable for debugging, compliance, and accountability purposes.

Scalability
In distributed systems, writing changes back to the original source can distribute the data updates across multiple nodes, improving the scalability and load balancing of your application.

Simplified Recovery
If a commit process fails midway, you can use the recorded changes to recover and reapply updates, ensuring data integrity.

Ease of Collaboration
When multiple users or systems interact with the same data source, writing changes back simplifies collaboration. Everyone sees the same data state, reducing confusion and conflicts.

Reduced Latency
In cases where data retrieval is time-consuming (e.g., fetching data from external APIs or databases), persisting changes locally can reduce latency by avoiding repetitive data fetches.

Easier Rollbacks
If a change leads to unexpected results or errors, reverting to the previous data state is more straightforward when changes are already stored in the original source.

Adherence to Data Policies
In scenarios with strict data governance or compliance requirements, writing changes back to the original data source ensures that data policies and access controls are consistently enforced.
Applying visualization and analysis to your data
Once your integrators are configured in Perspectives, the data is loaded into our in-memory native graph model which makes it effective and efficient to work with the data.
Perspectives makes it easy to design and configure an end-user web or desktop application that utilizes the graph model so your users can access the data in real-time. You configure easy-to-understand views of the data including graph drawings, tables, charts, timelines, maps and more. You can also incorporate powerful analytics into the resulting application so users gain even more insight into the data.
Watch this video to see how easy it is to configure a dashboard-style layout of views for your Perspectives application:
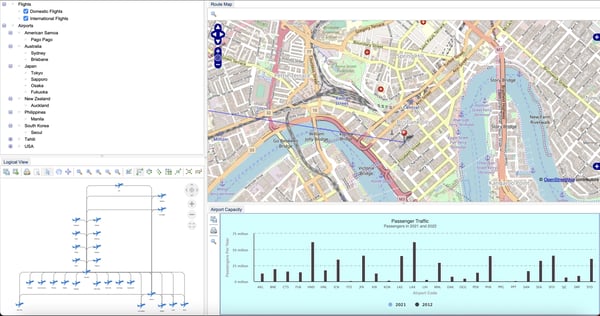
An example application created with Perspectives showing a dashboard layout with drawing, map, tree, and chart views.
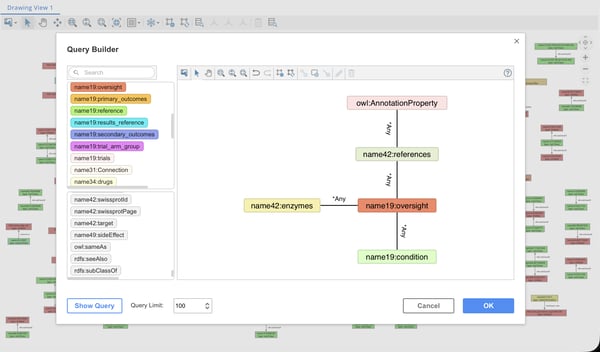
Query triple stores and labeled property graphs alike without the need to know SPARQL, Gremlin, or Cypher.
Eliminate the need to know complex query languages
You may not know every query that users will want to perform, that's why we created the Pattern Matching Query Builder, which greatly simplifies Analysts’ tasks for advanced graph pattern searches without the need to know the SPARQL, Gremlin, or Cypher query languages. The Pattern Matching Query Builder allows users to search for matching patterns in their graphs in triple stores and labeled property graphs alike.
However, if users know Cypher or Gremlin, they can enter their own queries directly. Adding this capability to your Perspectives application is seamless for developers, making data exploration more flexible and developer integration easier.
Improve data navigation and analysis with load neighbors
Load neighbors is an innovative feature in Perspectives that greatly improves the data navigation and analysis experience for end users. Load neighbors enables users to explore their data more effectively, saving them valuable time and allowing them to focus on their most important tasks.
With load neighbors, users can load data incrementally based on their use case by searching for graph patterns through an intuitive graph visualization. As a result, they can gain insights and make faster decisions, which is essential in today’s fast-paced business world.

Load data incrementally and gain insights faster with the Perspectives load neighbors feature.